Word Embedding: 一种分布式单词表示方式¶
前边我们谈到了one-hot编码的缺陷,这一节我们来聊另一种分布式的表示方式:Word Embedding,看他是怎么解决这些问题的。
假设每个单词都可以用\(n\)个特征进行表示,即可以使用这\(n\)个特征来刻画每个单词,如图2所示,我们使用图2中的这5个特征来刻画”狗”、”蜈蚣”、”君子兰”和”填空”这几个词。

显然,有了这些特征去构建词向量,我们能够根据这些特征比较容易地去划分单词的类别,比如”狗”和”蜈蚣”均是动物,在这个角度上说是一类的,他们之间的距离应该要比”狗”和”君子兰”近。
我们在回到词向量上来,按照同样的想法,可以使用这\(n\)个特征来刻画每个单词,并且这\(n\)个特征是浮点类型的,这样可以拓宽表示范围。当我们将视角切换到\(n\)维空间,那么每个词向量其实就相当于是该\(n\)维空间的一个点,相当于是将该单词嵌入到该空间中,这也是Word Embedding的原始意义。
当然我们通常是无法穷举具体的特征类别的,所以在NLP领域一般直接将模型表示为长度为\(n\)的向量让模型去训练(只是每个向量维度具体代表什么含义是不好去解释的)。但好消息是通过合适的词向量学习算法,是可以比较好的学习到单词的语义信息的,语义相近的单词之间的距离会比较近,语义不同的单词之间距离会比较远。
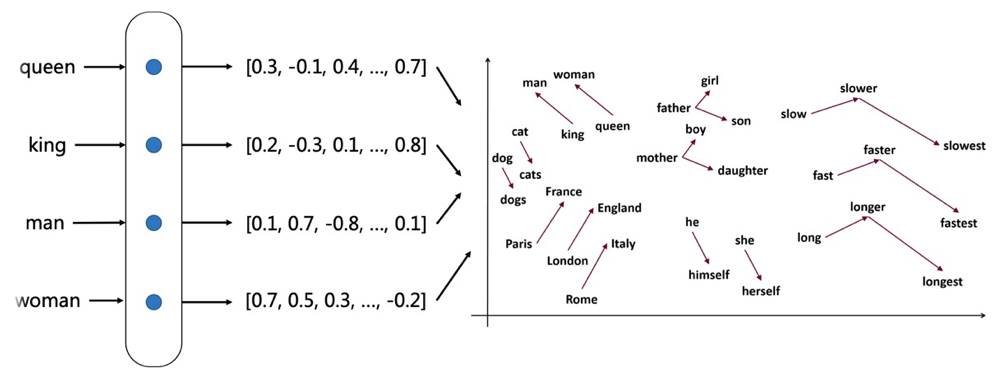
图3展示了关于词向量的一些例子,当我们将词向量训练好之后,我们可以看到France, England, Italy等国家之间比较近,并形成一个小簇;dog, dogs,cat,cats形成一个小簇。簇内的单词距离一般会比较近,不同簇的单词距离会比较远。