KBERT: Enabling Language Representation with Knowledge Graph¶
1. KBERT的由来¶
当前的预训练模型(比如BERT、GPT等)往往在大规模的语料上进行预训练,学习丰富的语言知识,然后在下游的特定任务上进行微调。但这些模型基本都没有使用**知识图谱(KG)**这种结构化的知识,而KG本身能提供大量准确的知识信息,通过向预训练语言模型中引入这些外部知识可以帮助模型理解语言知识。基于这样的考虑,作者提出了一种向预训练模型中引入知识的方式,即KBERT,其引入知识的时机是在fine tune阶段。在引入知识的同时,会存在以下两个问题:
Heterogeneous Embedding Space (HES): 通俗来讲,及时文本的词向量表示和KG实体的表示是通过独立不相关的两种方式分别训练得到的,这造成了两种向量空间独立不相关。
Knowledge Noise (KN):向原始的文本中引入太多知识有可能会造成歪曲原始文本的语义。
为了解决上边的两个问题,KBERT采用了一种语句树的形式向原始文本序列中注入知识,并在预训练模型的表示空间中获取向量表示;另外其还使用了soft-position和visible matrix的方式解决了KN问题。
2. KBERT的模型结构¶
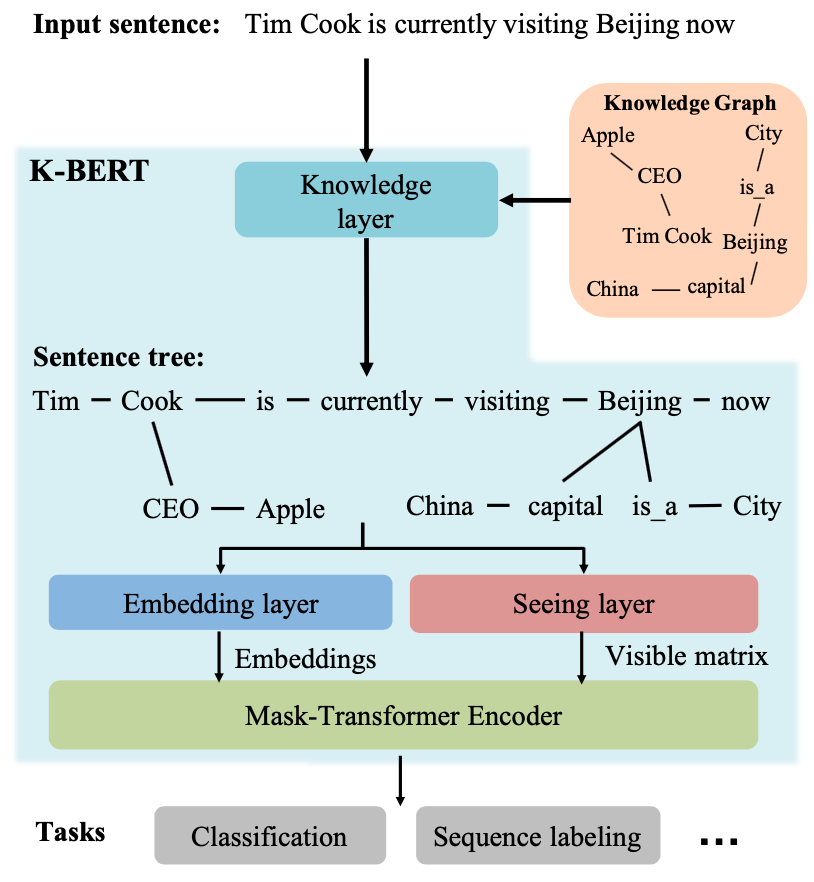
图1 展示了KBERT的模型结构,其中主要包含4个组件:Knowledge layer, Embedding layer, Seeing layer 和 Mask-Transformer Encoder。
对于输入的文本序列,KBERT会根据序列中存在的实体,在Knowledge Graph (KG)中找到相应的fact,例如<Cook, CEO, Apple>,然后在Knowledge layer中进行融合,并输出相应的Sentence tree。然后将其分别输入至Embedding layer和Seeing layer后分别得到token对应的Embedding和Visible matrix, 最后将两者传入Mask-Transformer Encoder中进行计算,并获得相应的输出向量。这些输出向量接下来将被应用于下游任务,比如文本分类,序列标注等。
这是关于KBERT整个的处理流程,其中比较核心的,也就是预训练模型和知识图谱融合的地方在Knowledge layer。下面我们来详细讨论KBERT模型的细节内容。
2.1 Knowledge layer: 构造Sentence tree 融合KG知识¶
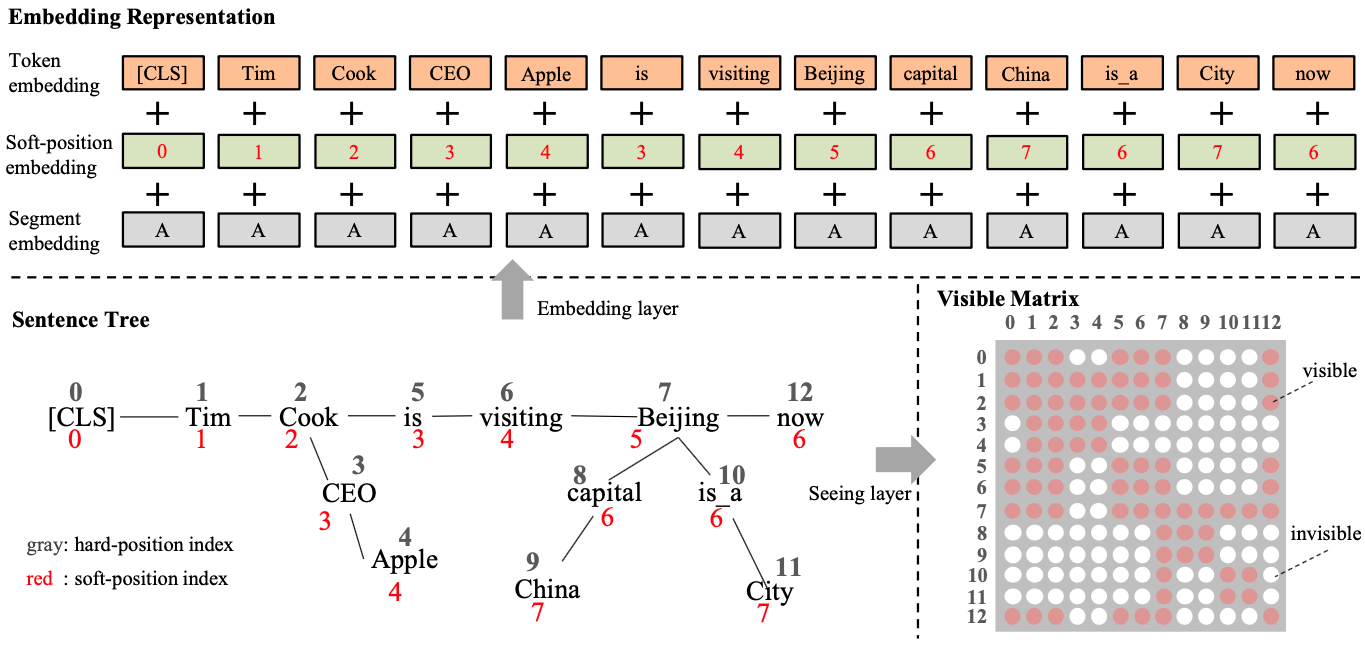
图2展示了KBERT整体的从构造Sentence tree 到生成相应的Embedding和Visible Matrix的过程。我们先来看Sentence tree生成这部分,其大致分为两个步骤:
找出文本序列中存在的实体,然后根据这些实体在KG中找出相应的事实三元组(fact triples)。
将找出的三元组注入到原始的文本序列中,生成Sentence tree。
给定一串文本序列[CLS, Time, Cook, is, visiting, Beijing, now], 序列中存在两个实体:Cook和Beijing,这两个实体在KG中的fact triples分别是<Cook, CEO, Apple>、<Beijing, captial, China>和<Beijing, is_a, City>,最后将这些三元组注入到原始的文本序列中生成Sentence Tree,如图2所示。
但这里需要注意的是,KBERT采用的BERT作为模型骨架,BERT的输入形式是一串文本序列,并不是上述的Sentence tree的形式,所以在实际输入的时候,我们需要对Sentence tree进行拉平,形成一串文本序列。这样的操作同时会带来一些问题:
直接拉平Sentence tree造成句子本身穿插fact triples,破坏了句子本身的语义顺序和结构,造成信息的混乱。
fact triples的插入造成上述的KN问题,歪曲原始句子本身的语义信息。
基于这些考虑,KBERT提出了soft-position和visible matrix两种技术解决这些问题。这些将会在以下两小节中进行展开讨论。
2.2 Embedding layer:引入soft-position保持语句本身的语序¶
从图2中可以看到,KBERT在Embedding层延用了BERT Embedding layer各项相加的方式,共包含三部分数据:token embedding、position embedding和segment embedding。不过为了将Sentence tree拉平转换成一个文本序列输入给模型,KBERT采用了一种soft-position位置编码的方式。
图2中红色的标记表示的就是soft-position的索引,黑色的表示的是拉平之后的绝对位置索引。在Embedding层使用的是soft-position,从而保持原始句子的正常的语序。
2.3 Seeing layer: Mask掉不可见的序列部分¶
Seeing layer将产生一个Visible Matrix,其将用来控制将Sentence tree拉平成序列后,序列中的词和词之间是否可见,从而保证想原始文本序列引入的fact triples不会歪曲原始句子的语义,即KN问题。
还是以图2展示的案例进行讨论,原始文本序列中的Beijing存在一个triple <Beijing, captial, China>,将这triple引入到原始文本序列后在进行Self-Attention的时候,China仅仅能够影响Beijing这个单词,而不能影响到其他单词(比如Apple);另外 CLS同样也不能越过Cook去获得Apple的信息,否则将会造成语义信息的混乱。因此在这种情况下,需要有一个Visible Matrix的矩阵用来控制Sentence tree拉平之后的各个token之间是否可见,互相之间不可见的token自然不会有影响。
如图2中展示的Visible Matrix,给出了由Sentence tree拉平之后的序列token之间的可见关系。
2.4 Mask-Transformer: 使用拉平后融入KG知识的序列进行transofmer计算¶
由于Visible Matrix的引入,经典的transofmer encoder部分无法直接去计算,需要做些改变对序列之间的可见关系进行mask, 这也是Mask-Transfomer名称的由来。详细公式如下:
其中, \(W_q\),\(W_k\)和\(W_v\)是可训练的模型参数,\(h_i\)是第\(i\)层Mask-Transformer的输出向量,\(d_k\)用于缩放计算的Attention权重,\(M\)是Seeing layer计算的Visible Matrix,它将会使得那些不可见的token之间的Self-Attention权重置0。