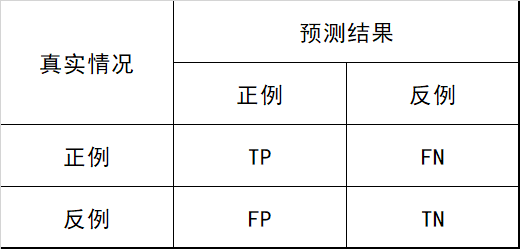
评估指标¶
机器学习的评价指标有精度、精确率、召回率、P-R曲线、F1 值、TPR、FPR、ROC、AUC等指标,还有在生物领域常用的敏感性、特异性等指标。
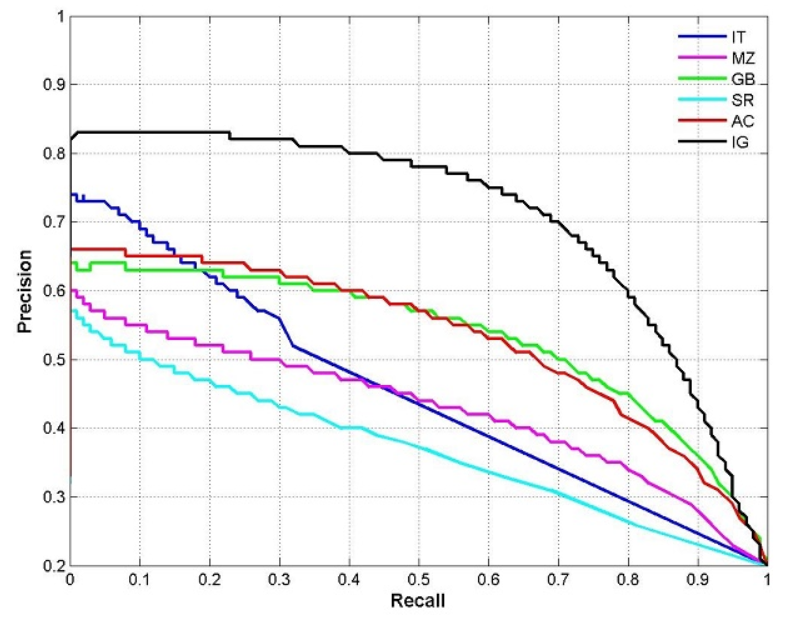
F1 值¶
\[F1=\frac{2 * P * R}{P + R}\]
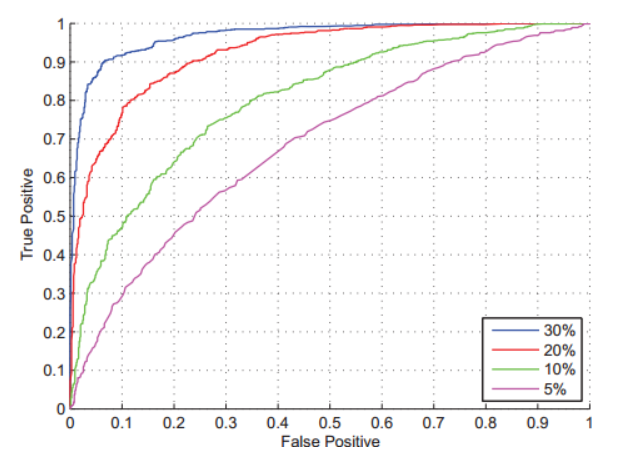
敏感性¶
敏感性或者灵敏度(Sensitivity,也称为真阳性率)是指实际为阳性的样本中,判断为阳性的比例(例如真正有生病的人中,被医院判断为有生病者的比例),计算方式是真阳性除以真阳性+假阴性(实际为阳性,但判断为阴性)的比值(能将实际患病的病例正确地判断为患病的能力,即患者被判为阳性的概率)。公式如下:
\[sensitivity =\frac{TP}{TP + FN}\]
即有病(阳性)人群中,检测出阳性的几率。(检测出确实有病的能力)
特异性¶
特异性或特异度(Specificity,也称为真阴性率)是指实际为阴性的样本中,判断为阴性的比例(例如真正未生病的人中,被医院判断为未生病者的比例),计算方式是真阴性除以真阴性+假阳性(实际为阴性,但判断为阳性)的比值(能正确判断实际未患病的病例的能力,即试验结果为阴性的比例)。公式如下:
\[specificity =\frac{TN}{TN + FP}\]
即无病(阴性)人群中,检测出阴性的几率。(检测出确实没病的能力)