Q-learning¶
介绍¶
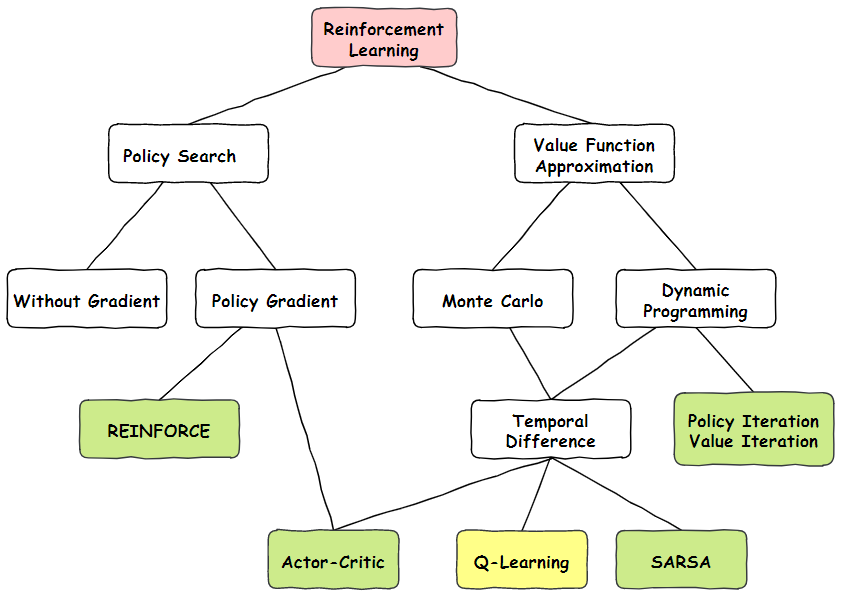 首先我们看一下上图Q-learning在整个强化学习的位置,Q-Learning是属于值函数近似算法中,蒙特卡洛方法和时间差分法相结合的算法。它在1989年被Watkins提出,可以说一出生就给强化学习带来了重要的突破。
首先我们看一下上图Q-learning在整个强化学习的位置,Q-Learning是属于值函数近似算法中,蒙特卡洛方法和时间差分法相结合的算法。它在1989年被Watkins提出,可以说一出生就给强化学习带来了重要的突破。
Q-Learning假设可能出现的动作a和状态S是有限多,这时a和S的全部组合也是有限多个,并且引入价值量Q表示智能体认为做出某个a时所能够获得的利益。在这种假设下,智能体收到S,应该做出怎样的a,取决于选择哪一个a可以产生最大的Q。下面的表格显示了动物在面对环境的不同状态时做出的a对应着怎样的Q,这里为了简单说明只分别列举了2种S和a:
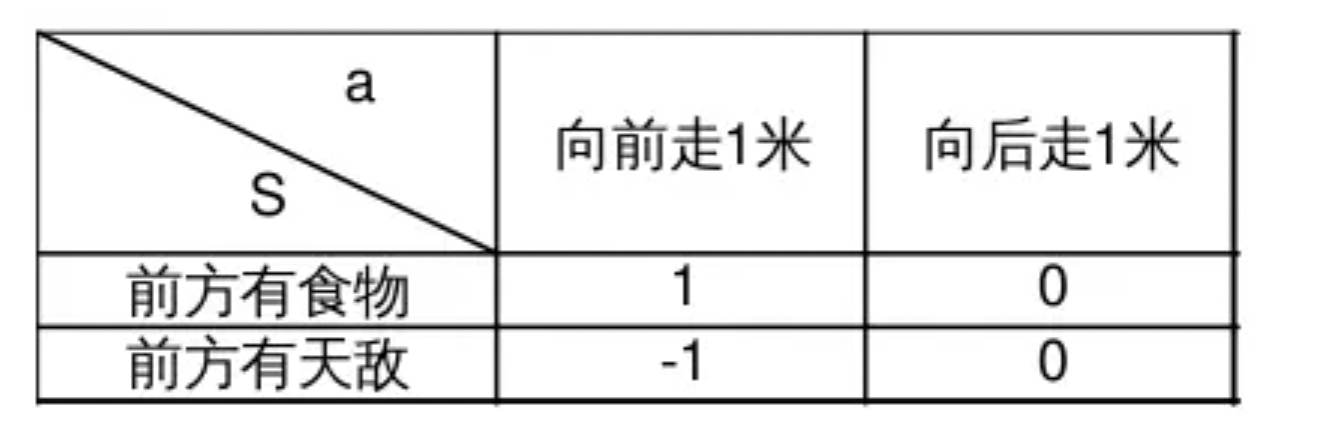
显然,如果此时S=”前方有食物”,选择a=”向前走1米”,得到的利益Q=”1” 显然比选择a=”向后走1米” 的q=”0”要大,所以这时应该选择向前走;相对的前方如果有天敌,往前走显然没有任何利益,这时选择最大的利益就要向后走。这种表格在Q-Learning中被称为Q表,表中的S和a需要事先确定,表格主体的数据——q在初始化的时候被随机设置,在后续通过训练得到矫正。
基础概念¶
Q-Learning的训练过程是Q表的Q值逐渐调整的过程,其核心是根据已经知道的Q值,当前选择的行动a作用于环境获得的回报R和下一轮\(S_{t+1}\)对应可以获得的最大利益Q,总共三个量进行加权求和算出新的Q值,来更新Q表:
其中 \(Q(S_{t+1}, a)\) 是在 \(t+1\) 时刻的状态和采取的行动(并不是实际行动,所以公式采用了所有可能采取行动的Q的最大值)对应的 Q 值,\(Q(S_{t},A_{t})\) 是当前时刻的状态和实际采取的形同对应的Q值。折扣因子\(\gamma\)的取值范围是 [ 0 , 1 ],其本质是一个衰减值,如果gamma更接近0,agent趋向于只考虑瞬时奖励值,反之如果更接近1,则agent为延迟奖励赋予更大的权重,更侧重于延迟奖励;奖励值\(R_{t+1}\)为t+1时刻得到的奖励值。\(\alpha\)为是学习率。
这里动作价值Q函数的目标就是逼近最优的\(q*\) \(q*=R_{t+1}+\gamma \mathop{max}_{a} Q(S_{t+1},a)\),并且轨迹的行动策略与最终的\(q*\)是无关的。后面中括号的加和式表示的是 \(q*\)的贝尔曼最优方程近似形式。
应用举例¶
将一个结冰的湖看成是一个4×4的方格,每个格子可以是起始块(S),目标块(G)、冻结块(F)或者危险块(H),目标是通过上下左右的移动,找出能最快从起始块到目标块的最短路径来,同时避免走到危险块上,(走到危险块就意味着游戏结束)为了引入随机性的影响,还可以假设有风吹过,会随机的让你向一个方向漂移。
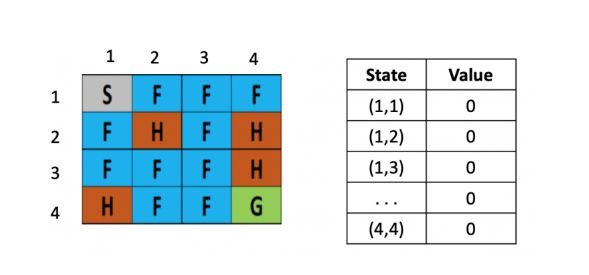
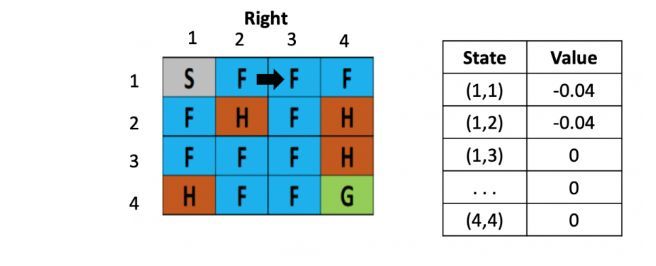
左图是每个位置对应的Q value的表,最初都是0,一开始的策略就是随机生成的,假定第一步是向右,那根据上文公式,假定学习率是\(\alpha\)是 0.1,折现率\(\gamma\)是0.5,而每走一步,会带来-0.4的奖励,那么(1.2)的Q value就是 0 + 0.1 ×[ -0.4 + 0.5× (0)-0] = -0.04,为了简化问题,此处这里没有假设湖面有风。
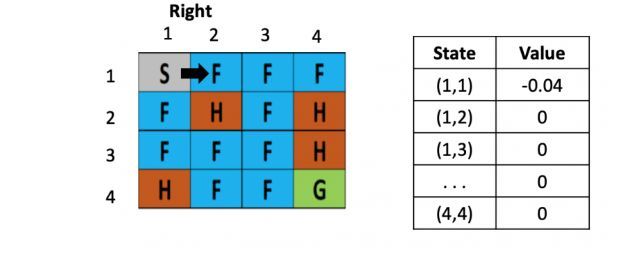
假设之后又接着往右走了一步,用类似的方法更新(1,3)的Q value了,得到(1.3)的Q value还为-0.04
等到了下个时刻,骰子告诉我们要往左走,此时就需要更新(1,2)的Q-value,计算式为:V(s) = 0 +0.1× [ -0.4 + 0.5× (-0.04)-0) ]
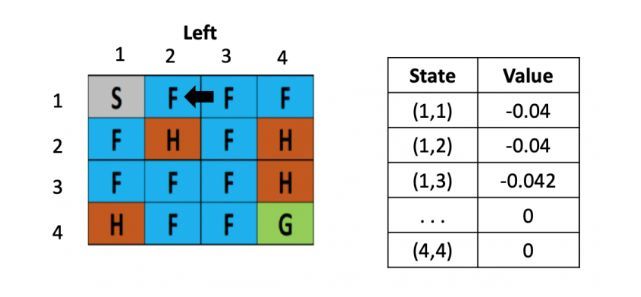
从这里,智能体就能学到先向右在向左不是一个好的策略,会浪费时间,依次类推,不断根据之前的状态更新左边的Q table,直到目标达成或游戏结束。
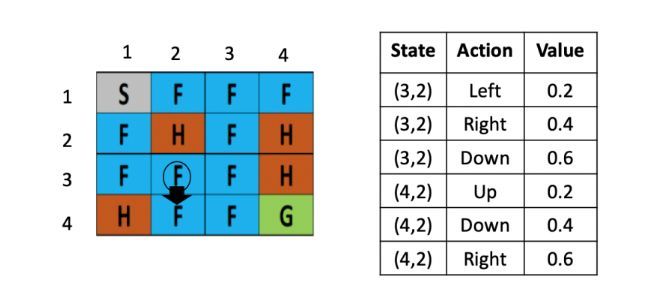
假设现在智能体到达了如图5所示的位置,现在要做的是根据公式,更新(3,2)这里的Q value,由于向下走的Q-value最低,假定学习率是0.1,折现率是0.5,那么(3,2)这个点向下走这个策略的更新后的Q value就是:
优缺点¶
Q-Learning算法有一些缺点,比如状态和动作都假设是离散且有限的,对于复杂的情况处理起来会很麻烦;智能体的决策只依赖当前环境的状态,所以如果状态之间存在时序关联那么学习的效果就不佳。