Actor-Critic¶
介绍¶
在 REINFORCE 算法中,每次需要根据一个策略采集一条完整的轨迹,并计算这条轨迹上的回报。这种采样方式的方差比较大,学习效率也比较低。我们可以借鉴时序差分学习的思想,使用动态规划方法来提高采样的效率,即从状态 \(s\) 开始的总回报可以通过当前动作的即时奖励 \(r(s,a,s')\) 和下一个状态 \(s'\) 的值函数来近似估计。
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,包括两部分,演员(Actor)和评价者(Critic),跟生成对抗网络(GAN)的流程类似:
演员(Actor)是指策略函数 \(\pi_{\theta}(a|s)\),即学习一个策略来得到尽量高的回报。用于生成动作(Action)并和环境交互。
评论家(Critic)是指值函数 \(V^{\pi}(s)\),对当前策略的值函数进行估计,即评估演员的好坏。用于评估Actor的表现,并指导Actor下一阶段的动作。
借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
在Actor-Critic算法 里面,最知名的方法就是 A3C(Asynchronous Advantage Actor-Critic)。
如果去掉 Asynchronous,只有 Advantage Actor-Critic,就叫做
A2C。如果加了 Asynchronous,变成Asynchronous Advantage Actor-Critic,就变成
A3C。
Actor-Critic¶
Q-learning¶
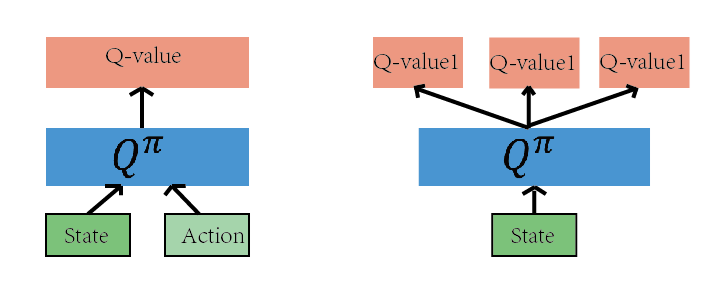
如上图的网络都是为了近似 Q(s,a)函数,有了 Q(s,a),我们就可以根据Q(s,a)的值来作为判断依据,作出恰当的行为。
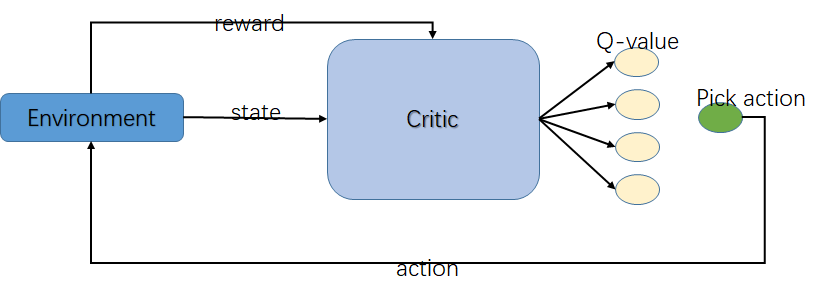
Q-learning算法最主要的一点是:决策的依据是Q(s,a)的值。即算法的本质是在计算 当前状态s, 采取某个动作 a 后会获得的未来的奖励的期望,这个值就是 Q(s,a)。换句话说,我们可以把这个算法的核心看成一个评论家(Critic),而这个评论家会对我们在当前状态s下,采取的动作a这个决策作出一个评价,评价的结果就是Q(s,a)的值。
Q-learning 算法却不怎么适合解决连续动作空间的问题。因为如果动作空间是连续的,那么用Q-learning算法就需要对动作空间离散化,而离散化的结果会导致动作空间的维度非常高,这就使得Q-learning 算法在实际应用起来很难求得最优值,且计算速度比较慢。
Policy Gradient¶
Policy Gradient 算法的核心思想是: 根据当前状态,直接算出下一个动作是什么或下一个动作的概率分布是什么。即它的输入是当前状态 s, 而输出是具体的某一个动作或者是动作的分布。
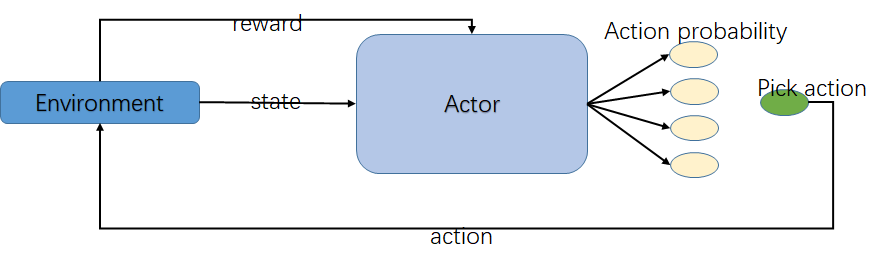
我们可以想像,Policy Gradient 就像一个演员(Actor),它根据某一个状态s,然后作出某一个动作或者给出动作的分布,而不像Q-learning 算法那样输出动作的Q函数值。
Actor Critic¶
Actor-Critic 是Q-learning 和 Policy Gradient 的结合。 为了导出 Actor-Critic 算法,必须先了解Policy Gradient 算法是如何一步步优化策略的。
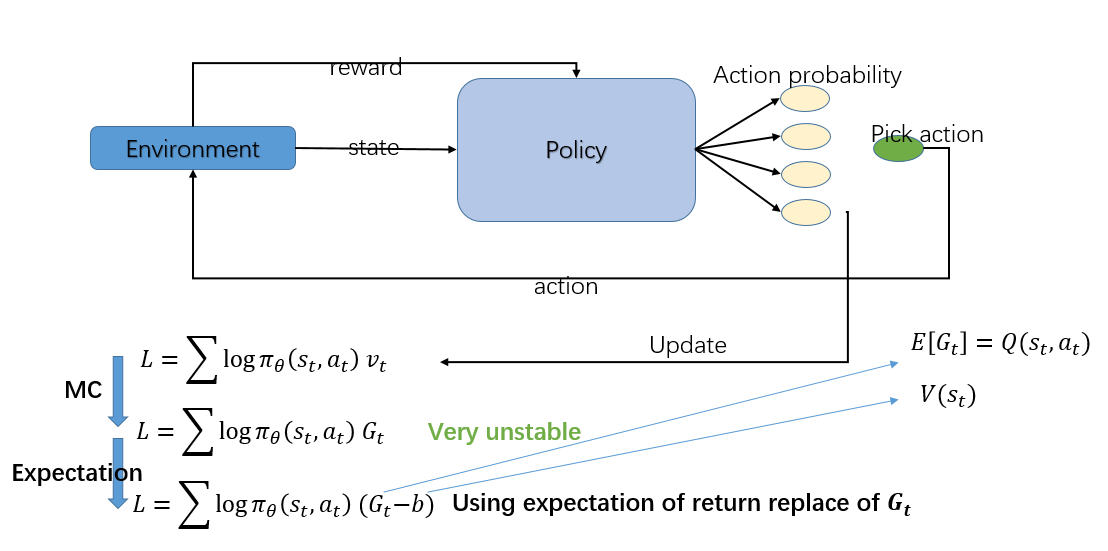
如上图所示, 最简单的Policy Gradient 算法要优化的函数如下:
其中\(v_{t}\)要根据 Monte-Carlo 算法估计,故又可以写成:
但是这个\(G_{t}\)方差会比较大,因为\(G_{t}\)是由多个随机变量得到的,因此,我们需要寻找减少方差的办法。
一个方法就是引入一个 baseline 的函数 b, 这个 b 会使得\((G_{t}-b)\)的期望不变,但是方差会变小,常用的 baseline函数就是\(V(s_{t})\)。再来,为了进一步降低\(G_{t}\)的随机性,我们用\(E(G_{t})\)替代\(G_{t}\),这样原式就变成:
因为\(E(G_{t}|s_{t},a_{t})=Q(s_{t},a_{t})\),故进一步变成:
照上面的式子看来,我们需要两个网络去估计\(Q(s_{t},a_{t})\)和\(V(s_{t})\),但是考虑到贝尔曼方程:
弃掉期望:
在原始的A3C论文中试了各种方法,最后做出来就是直接把期望值拿掉最好,这是根据实验得出来的。 最终的式子为:
这样只需要一个网络就可以估算出V值了,而估算V的网络正是我们在 Q-learning 中做的,所以我们就把这个网络叫做 Critic。这样就在 Policy Gradient 算法的基础上引进了 Q-learning 算法了
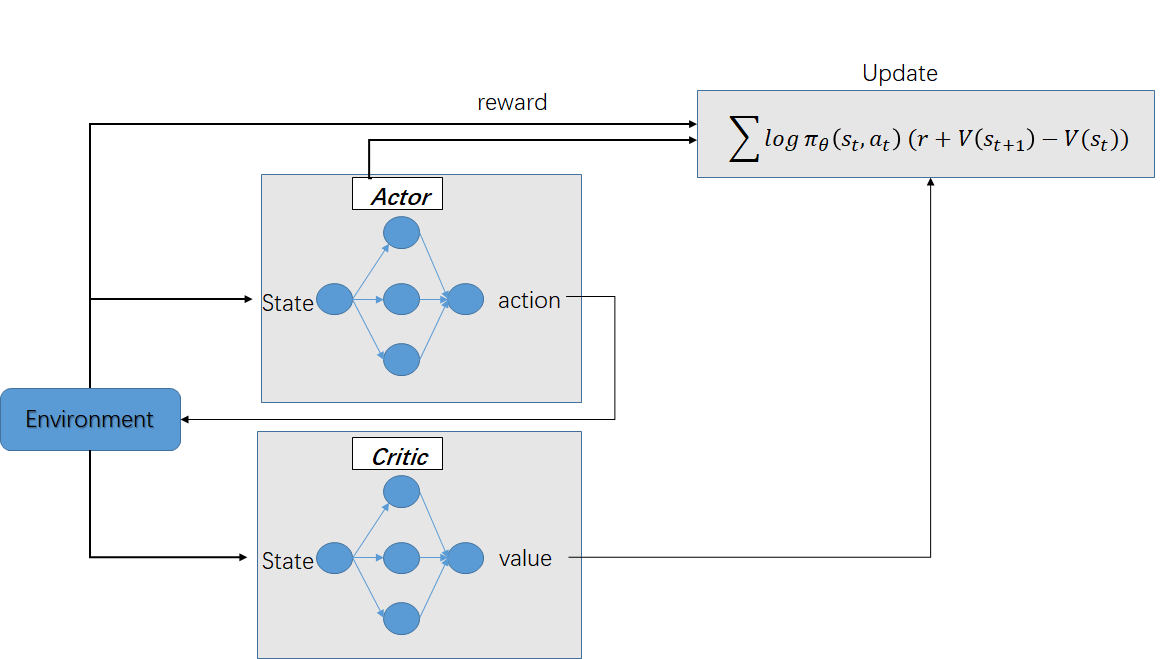
Actor-Critic算法流程¶
评估点基于TD误差,Critic使用神经网络来计算TD误差并更新网络参数,Actor也使用神经网络来更新网络参数
输入:迭代轮数T,状态特征维度n,动作集A,步长\(\alpha\),\(\beta\),衰减因子\(\gamma\),探索率\(\epsilon\), Critic网络结构和Actor网络结构。
输出:Actor网络参数\(\theta\),Critic网络参数\(w\)
随机初始化所有的状态和动作对应的价值Q;
for i from 1 to T,进行迭代:
初始化S为当前状态序列的第一个状态,拿到其特征向量\(\phi (S)\)
在Actor网络中使用\(\phi (S)\)作为输入,输出动作A,基于动作A得到新的状态S’,反馈R;
在Critic网络中分别使用\(\phi (S)\),\(\phi (S')\)作为输入,得到Q值输出V(S),V(S’);
计算TD误差\(\delta=R+\gamma V(S')-V(S)\)
使用均方差损失函数\(\sum (R+\gamma V(S')-V(S,w))^2\)作Critic网络参数w的梯度更新;
更新Actor网络参数\(\theta\): $\(\theta=\theta+\alpha \nabla_{\theta} log \pi_{\theta}(S_{t},A)\delta \)$
对于Actor的分值函数\(\nabla_{\theta} log \pi_{\theta}(S_{t},A)\),可以选择softmax或者高斯分值函数。
Actor-Critic优缺点¶
优点¶
相比以值函数为中心的算法,Actor - Critic 应用了策略梯度的做法,这能让它在连续动作或者高维动作空间中选取合适的动作,而Q-learning 做这件事会很困难甚至瘫痪。、
相比单纯策略梯度,Actor - Critic 应用了Q-learning 或其他策略评估的做法,使得Actor Critic 能 进行单步更新而不是回合更新,比单纯的Policy Gradient 的效率要高。
缺点¶
基本版的Actor-Critic算法虽然思路很好,但是难收敛
目前改进的比较好的有两个经典算法:
DDPG算法,使用了双Actor神经网络和双Critic神经网络的方法来改善收敛性。
A3C算法,使用了多线程的方式,一个主线程负责更新Actor和Critic的参数,多个辅线程负责分别和环境交互,得到梯度更新值,汇总更新主线程的参数。而所有的辅线程会定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用,但是效果更好。