XLNet:Generalized Autoregressive Pretraining for Language Understanding¶
1. 从AR和AE模型到XLNet模型¶
自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序列概率,要么从后向前计算文本序列概率,但不论哪种方式的建模,都是单向的。即在预测一个单词的时候无法同时看到该单词位置两边的信息。假设给定的文本序列\(x=(x_1, x_2, ..., x_n)\),其从左到右的序列生成概率为:
自编码模型(Autoencoding Model, AE), 通过从破坏的输入文本序列中重建原始数据进行建模。例如BERT通过预测【mask】位置的词重建原始序列。它的优点在于在预测单词的时候能够同时捕获该单词位置前后双向的信息;它的缺点是预训练过程中采用了mask单词的策略,然而微调阶段并没有,因此导致了预训练阶段和微调阶段的的GAP,另外在训练过程中,对不同mask单词的预测是相互独立的。假设序列中被mask的词为\(w\in W_m\),未被mask的词为\(w\in W_n\),则其相应的计算概率为:
这里对传统的AR和AE模型简单总结一下,AR模型是生成式模型,是单向的;AE模型是判别式模型,是双向的。鉴于传统的AR模型和AE模型自身的优点和缺点,XLNet期望能够融合两者的优点同时又避免两者的缺点,这就是XLNet的设计思路。
整体上XLNet是基于AR模型的建模思路设计的,同时避免了只能单向建模的缺点,因此它是一种能看得见双向信息的广义AR模型。作为一个AR模型,XLNet并没有采用预测mask单词的方式进行建模,因此它不存在上述预训练-微调的GAP,更不存在预测mask的独立性假设。
2. Permutation Language Model¶
Permuatation Language Mode (下文将简称为PLM) 是XLNet的核心建模思路,在正式介绍之前,我们再来回顾一下AR模型的建模策略,给定一串文本序列\(\text{x}=[x_1,x_2,...,x_n]\),其中每个\(x_i\)表示一个token,AR模型的通过最大化下边这个似然函数进行建模:
这里,\(\text{x}_{<t}\)表示在\(t\)位置前边的token序列,\(h_{\theta}(\text{x}_{1:t-1})\)表示数据由模型产生的上下文向量,\(e(x_t)\)表示token \(x_t\)的embedding。
这种建模方式是单向的,为了在预测某个位置单词的时候,能够让模型看见双向的信息,XLNet采用了全排列的思路,允许模型在不同文本序列排列上进行建模,但模型的参数在不同序列上是共享的,相当于是模型能够看见预测位置单词左右两侧的信息。
举个例子,假设当前有文本序列\(\text{x}=[x_1,x_2,x_3]\),这串序列中共有3个token,这三个token共计有6种排列组合方式,其相关的索引序列为:
\(\text{z}_1 = (1,2,3)\)
\(\text{z}_2=(1,3,2)\)
\(\text{z}_3=(2,1,3)\)
\(\text{z}_4=(2,3,1)\)
\(\text{z}_5=(3,1,2)\)
\(\text{z}_6=(3,2,1)\)
采用索引序列\(\text{z}_1\)的文本序列为\(\text{x}=[x_1, x_2, x_3]\),采用索引序列\(\text{z}_2\)的文本序列为\(\text{x}=[x_1, x_3, x_2]\),如果模型在训练过程中能同时看到这样的两个排列,那么在预测\(x_2\)的时候将可以看到\(x_1\),又可以看到\(x_3\),因为训练过程中模型的参数是共享的,因此相当于模型能够看到\(x_2\)前后双向的信息。
下面正式归纳一下XLNet的目标函数,假设给定一串序列\(\text{x}=[x_1,x_2,x_3,...,x_n]\),它将有\(n!\)个不同的排列组合\(\mathbb{Z}=[\text{z}_1,\text{z}_2,...,\text{z}_{n!}]\),令\(\text{z}\in \mathbb{Z}\)表示某一排列方式,\(z_{t}\)表示为\(\text{z}\)这个排列的第\(t\)个位置,\(\text{z}_{<t}\)表示\(t\)这个位置前边的\(t-1\)个位置编号,\(\text{x}_{\text{z}}\)表示将序列\(\text{x}\)按照索引\(\text{z}\)进行排序。\(\text{x}_{\text{z}<t}\)表示将原始\(\text{x}\)按照\(\text{z}\)进行排列后,\(\text{x}_{\text{z}}\)前\(t-1\)个位置的token。另外假设排列\(\text{z}\)出现的概率为\(p(\text{z})\),则XLNet的正式目标函数依据极大似然估计为:
但是一个长度为\(n\)的文本序列,其排列组合数为\(n!\),数量实在庞大,不便训练,所以在实际训练过程中,XLNet是通过采样的方式逼近目标函数的期望,即:
其中,\(z_{it}\)表示第\(i\)个排列的第\(t\)个位置,\(\text{x}_{\text{z}_i<t}\)表示按照\(\text{z}_i\)排列进行重塑后的前\(t-1\)个token。每次采样一个排列顺序\(\text{z}\)进行重塑原始序列\(\text{x}_{\text{z}}\),然后将\(\text{x}_\text{z}\)进行分解组合计算:\(\sum_{t=1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{\text{z}<t}) \)。这里需要注意的是,XLNet只是调整了联合概率\(p(\text{x})\)的分解顺序,但是原始token之间的顺序是不变的,即token之间还是使用原始顺序的position embedding,\(p(\text{x})\)的分解顺序的计算主要是通过transformer的mask机制实现的。这样的设定也保证了预训练阶段和微调阶段之间的顺序是一致的,均是正常的自然语序。
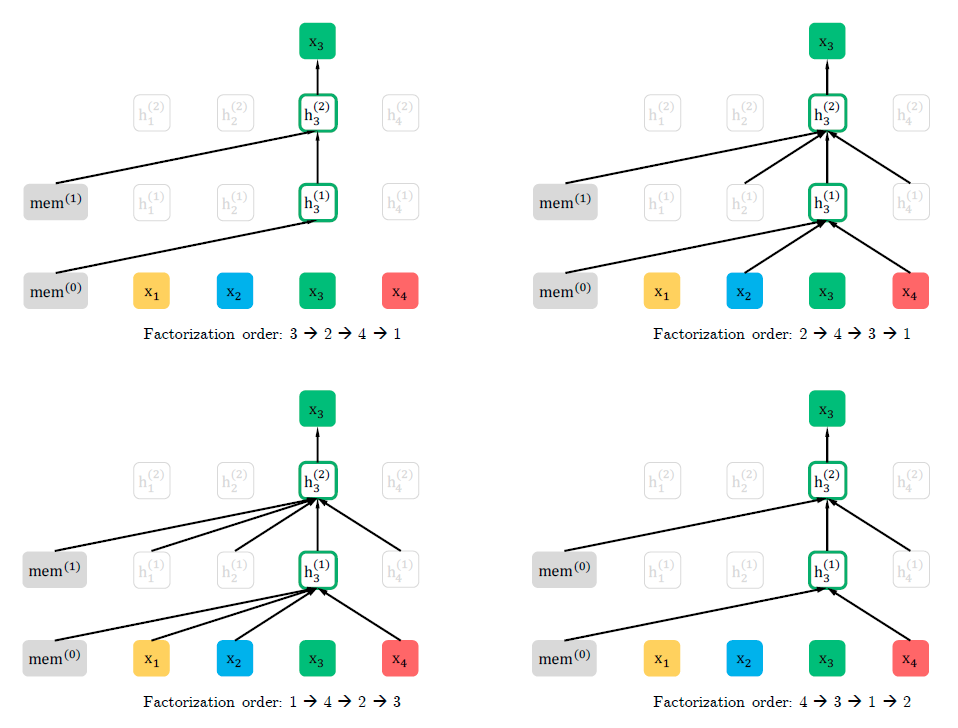
图1中\(mem^{(0)}\)和\(mem^{(1)}\)代表前一个的segment的缓存信息,另外,输入的序列顺序都是固定的自然语序,position embedding还是按照正常的顺序确定的。只是不同的排列中,参与分解计算的内容不同。具体来讲,对第一个分解次序\(3\rightarrow2\rightarrow4\rightarrow1\),因为\(x_3\)位于最前边,所以在这个分解次序中看不到其他的token内容,只能看到前一个segment的缓存信息;对第一个分解次序\(2\rightarrow4\rightarrow3\rightarrow1\),\(x_3\)前边有\(x_2\)和\(x_4\),所以在计算\(x_3\)位置输出的时候使用了\(x_2\)和\(x_4\)。
这个想法就是PLM的建模思路,看到这里,相信你已经很好地理解了。
3. Permutation Language Model如何建模¶
3.1 使用经典的transformer是否能建模PLM¶
上边看似找到了一个比较好想法去让AR模型在预测一个单词的时候同时能够看到前后双向的信息,但具体怎么来建模实现呢?使用原始的transformer技术直接实现可能会带来一些问题,具体来说,假设当前有两个排列\(\text{z}^{1}\)和\(\text{z}^2\),他们之间具有如下的关系:
这种情况下,使用经典transformer的方式去预测这两个排列\(z_t\)位置的输出,将会有:
显然在这种情况下,预测第\(i\)个位置的单词和预测第\(j\)个位置的单词的概率分布是相同的,这肯定是不对的,因此使用经典的transformer是无法去做Permutation Language Model建模的。
为了解决这个问题,XLNet在预测目标\(z_t\)位置的token时,向其引入了位置信息\(z_t\),重新定义的预测token概率分布的计算方式为:
从公式中可以看到,其在预测\(z_t\)位置token的时候,引入了位置信息\(z_t\)。这样就能解决上述的问题,即经过这个变换后上式将变为:
3.2 使用Two-Stream Self-Attention建模PLM¶
从上边讨论的这些可以看到,当预测\(z_t\)位置的token时,最多只能使用位置信息\(z_t\),而不能使用该\(z_t\)对应的内容\(x_{z_t}\),否则,就相当于使用\(x_{z_t}\)来预测\(x_{z_t}\)自己,这没有什么意义;当预测\(j>t\)后的token \(x_{z_j}\)时,不仅需要位置信息\(z_t\),同时还需要该位置对应的内容\(x_{z_t}\)。
然而,经典的transformer中是将两者信息在输入层相加融合之后进行后续计算的,因此XLNet提出了一种双流自注意力机制:content-stream 和 query stream,下面我们将来具体探讨一下它们。
content-stream 提供了内容方面的表达 content representation \(h_{\theta}(\text{x}_{\text{z}_{\leq t}} )\),简记为\(h_{z_t}\),它等同经典的transformer 的状态向量,这个向量中既包含了位置信息\(z_t\),又包含了内容信息\(x_{z_t}\)。
query-stream 提供了查询方面的表达 query representation \(g_{\theta}(\text{x}_{\text{z}_{<t}}, z_t)\),简记为\(g_{z_t}\),它仅仅包含了\(x_{z<t}\)的内容信息和\(z_t\)的位置信息,并不包含\(x_{z_t}\)的内容。
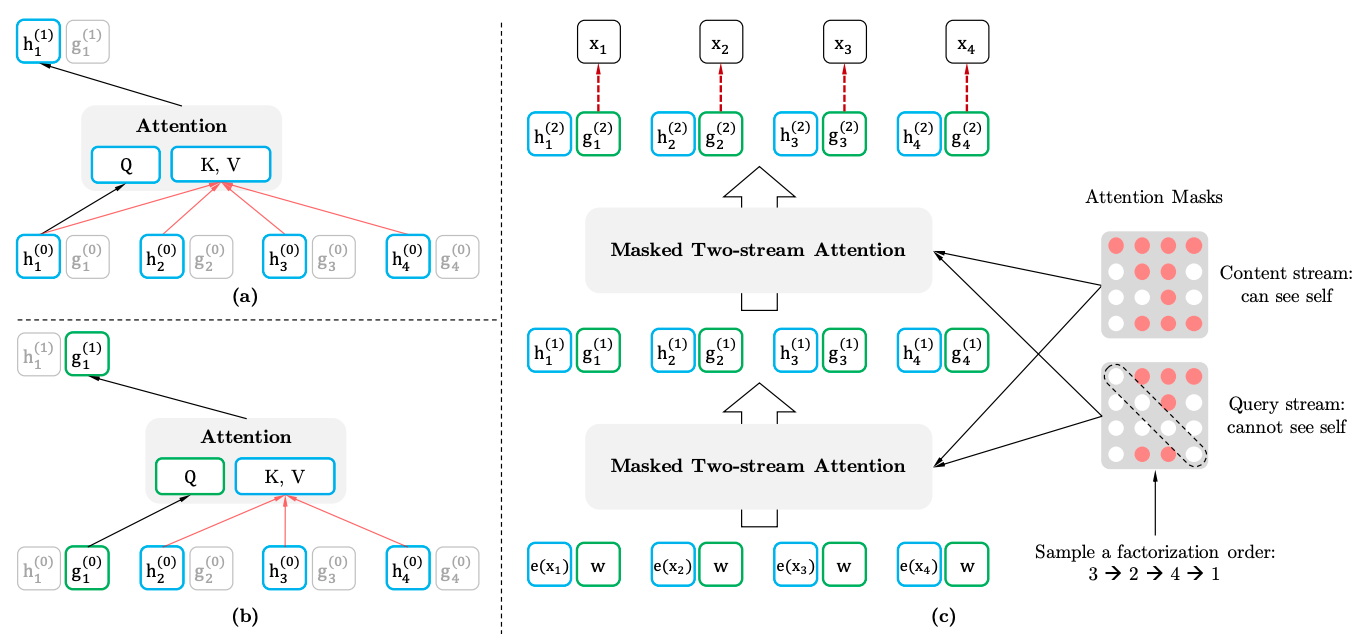
图2展示了分解顺序为\(3 \rightarrow 2 \rightarrow 4 \rightarrow 1\)的two-stream计算过程,我们通过这张图来具体聊聊如何去定义\(g_{\theta}(\text{x}_{\text{z}_{<t}},z_t)\)。
图2a展示了content-stream的自注意力计算,其中\(h_i^{(0)}\)是由token的embedding进行初始化,可以看到它的计算和经典的transormer是一致的,因为在分解顺序中1位于最后,因此它能看见前边所有的token内容,最终计算得出的\(h_1^{(1)}\)同时包含了第\(1\)个位置的内容信息。
图2b展示了query-stream的自注意力计算,其中\(g_i^{(0)}\)由可学习的参数进行初始化,因为它能看见token 3,2,4的内容信息,所以这里用的是内容信息\(h_3^{(0)},h_2^{(0)},h_4^{(0)}\),同时对于第1个位置,只能使用位置信息,而不能使用内容信息,所以这里使用的是\(g_1^{(0)}\),它并不包含第1个位置的内容信息。 这样就能比较好地建模\(g_{\theta}(\text{x}_{\text{z}_{<t}},z_t)\)。
图2c展示了整体的计算流程,最后一层输出的query向量就是我们想要的\(g_{\theta}(\text{x}_{\text{z}_{<t}},z_t)\)。右边的两个矩阵分别展示了content-stream和query-stream的mask矩阵内容,就是使用这样的mask矩阵来计算序列分解式的。 关于这两个流的Self-Attention计算公式如下:
以上是XLNet在预训练阶段的计算过程,这里需要注意的是,在微调阶段,XLNet仅仅使用content respresentation进行fine-tune下游任务。
3.3 引入Transformer-XL的想法¶
由于XLNet本身是个AR模型,它可以完美融入Transformer-XL的思想:相对位置编码和segment循环机制。这两者的原理部分感兴趣的同学可以去阅读Transformer-XL内容,本文重点讨论一下segment循环机制向XLNet的融入过程。
顾名思义,segment循环机制是指长序列切分成\(n\)个segment (文本片段),然后将每个segment依次传入模型之中,同时传入到模型中,同时传入到模型中还有上一个segment的产生的输出,这个操作有点像RNN,接收上一步的输出和当前步骤的输入,然后根据两者计算产生当前步骤的输出,只不过RNN的循环单位是单词,XLNet的循环单位是segment。
给定一个长序列\(\text{s}\),上一个segment为\(\tilde{\text{x}}=s_{1:n}\),其对应的排列用\(\tilde{\text{z}}\)表示;当前的segment为\(\text{x}=s_{n+1:2n}\),其对应的排列用\(\text{z}\)表示。基于排列\(\tilde{\text{z}}\)处理第1个segment,并将其输出进行缓存,第\(m\)层的输出用\(\tilde{h^{(m)}}\)表示。则第2个segment的计算可以按照如下方式进行:
即将前一个segment的输出和当前位置\(z_t\)能看到的内容进行拼接,然后进行Self-Attention融合计算。
这里需要注意的是,由于序列中的position embedding 仅仅依赖于原始序列(输入序列)的位置,而不是排列的顺序,所以一旦前一个segment的输出\(\tilde{h}^{(m)}\)确定,上述的Attention计算和前一个segment的分解顺序无关。这允许我们去缓存或者复用前一个segment的输出,而不用去管前一个segment的分解顺序。
3.4 关于XLNet的一些Trick¶
3.4.1 Partial Prediction¶
最开始的时候有提到,AR模型通过估计一串文本序列的生成概率分布进行建模:\(\sum_{t=1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{\text{z}<t}) \)。PLM虽然解决了AR模型建模过程中的双向问题,但是由于通过这种排列组合的形式训练,导致XLNet收敛会比较慢。
因此XLNet在训练过程中,只选择预测序列最后面的部分位置的token,这里涉及到一个切分点位置\(c\),它将指示不预测在\(c\)前边的位置\(\text{z}_{\leq c}\),只预测\(c\)后边的位置\({\text{z}_{>c}}\)。XLNet中切分点\(c\) 的选择由超参数\(K\)来确定,\(K \approx \frac{n}{n-c}\),其中\(n\)为序列长度。\(K\)越大,则需要预测的token数量越少。
这就是Partial Prediction 部分预测,对于切分点\(c\)之前的token无需计算query representation,这会大大节省内存,加快模型训练速度。加入切分点后,XLNet的目标函数将变为:
3.4.2 Multiple Segment Input¶
许多下游任务存在多段输入的情况,比如QA任务中包含query( 简记为A )和answer (简记为B)两个部分,数据的输入形式同BERT一致:\(\text{[CLS, A, SEP, B, SEP]}\)。
但是在segment循环的时候,每个部分仅仅使用对应上下文的状态缓存。
3.4.3 Relative Segment Encoding¶
Relative Segment Encoding (相对段编码) , 这里的Segment不是上边将的将序列划分为固定的Segment,而是指输入数据的不同部分,例如\(\text{[CLS, A, SEP, B, SEP]}\),\(\text{A}\)和\(\text{B}\)分别属于不同的Segment。
BERT直接使用了绝对编码,直接给\(\text{A}\)和\(\text{B}\)中的token依次设置了0和1,用来指示整个序列中\(\text{A}\)和\(\text{B}\)是不同的segment,即是不同的文本段,例如一个是query,另一个是answer。
XLNet与BERT不同,它使用了相对编码,给定序列中的两个位置\(i\)和\(j\),判断这两个位置对应的token是否在同一个segment里面,如果两者在同一个segment里面,\(s_{ij}=s_+\),否则\(s_{ij}=s_-\)。 当预测第\(i\)个位置token的时候,需要计算用\(i\)位置的向量向另一位置\(j\)做attention获取分数,其按照如下公式计算:
其中\(q_i\)为第\(i\)个位置的查询向量,\(b\)是一个可学习的参数。最终\(a_{i,j}\)将被加到正常Self-Attention的注意力分数上。
使用相对段编码有这样的优势:
模型的泛化效果会更好;
在微调任务上,它支持超过两个segment输入的下游任务(虽然预训练过程中使用了两个segment);